什么是交叉验证?
交叉验证(Cross Validation)是一种在数据科学和机器学习中广泛应用的技术,主要用于评估模型的性能,确保模型不仅能够在训练数据上表现良好,也能在未见过的新数据上保持良好的预测能力。简单来说,它是一种“测试模型稳定性和可靠性”的方法。
通过交叉验证,我们可以解决模型在训练过程中可能遇到的一些问题,比如过拟合或评估偏差,尤其是在数据有限的情况下。
为什么需要交叉验证?
模型训练的目标是让模型在新数据上表现良好,而不仅仅是在训练数据上取得高分。但在实践中,如果我们只是在固定的训练集和测试集上评估模型,可能会导致以下问题:
- 过拟合(Overfitting): 模型过于适应训练数据的特点,在新数据上表现不佳。
- 欠拟合(Underfitting): 模型过于简单,无法捕捉数据的真实模式。
- 评估偏差: 单次划分可能选中一些特殊的样本,导致结果缺乏代表性。
- 数据浪费: 如果直接划分训练集和测试集,有一部分数据被永久分配为测试集,无法用于训练,导致数据利用率降低。
交叉验证通过将数据集分成多个部分,轮流进行训练和测试,可以最大限度地利用数据,减少上述问题。
交叉验证的工作原理
交叉验证的基本思想是:将数据集划分为多个子集(或称为“折”),在不同的子集上重复训练和测试,从而对模型性能进行全面的评估。
以下是几种常见的交叉验证方法:
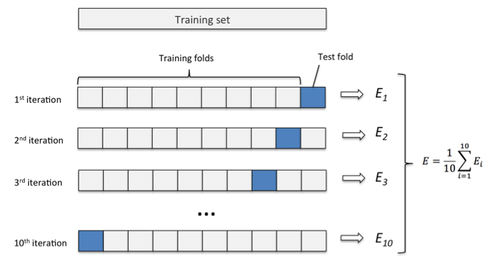
1. k折交叉验证(k-Fold Cross Validation)
这是最经典的交叉验证方法。具体步骤如下:
- 将数据集随机分成k个子集,称为“折”。
- 每次选择一个子集作为测试集,其余k-1个子集作为训练集。
- 重复k次,确保每个子集都被用作一次测试集。
- 最终,将k次测试的结果取平均,作为模型的性能评估结果。
举例来说,如果k=5:
- 第一次:用第1折做测试集,剩余4折做训练集。
- 第二次:用第2折做测试集,剩余4折做训练集。
- 以此类推,直到所有5折都被用作测试集。
优点:
- 充分利用了所有数据。
- 减少了单次数据划分可能带来的评估偏差。
缺点:
- 如果数据量大或模型复杂,计算时间较长。
2. 留一法(Leave-One-Out Cross Validation, LOOCV)
这是k折交叉验证的极端形式,其中k等于数据集的样本数量。每次选择一个样本作为测试集,其他所有样本作为训练集。
优点:
- 使用了几乎所有数据进行训练,评估结果非常接近真实性能。
缺点:
- 计算成本极高,特别是当数据集很大时。
3. 分层k折交叉验证(Stratified k-Fold Cross Validation)
对于分类问题,如果数据的类别分布不均衡(例如正负样本比例差距较大),普通的k折交叉验证可能导致某些折中类别分布不均匀,影响评估结果。
分层k折交叉验证确保每个折中的类别分布与整体数据集一致,从而避免评估偏差。
4. 时间序列交叉验证(Time Series Cross Validation)
对于时间序列数据,普通的k折交叉验证会打乱时间顺序,可能导致模型在评估时使用了未来的信息,这是不合理的。
时间序列交叉验证按照时间顺序划分数据,例如:
- 第1次:使用最早的20%数据训练,后续10%数据测试。
- 第2次:使用最早的30%数据训练,再用后续10%数据测试。
- 依此类推,直到最后。
适用场景:
- 金融预测。
- 销量预测。
- 其他时间相关任务。
5. 随机分割交叉验证(Shuffle Split Cross Validation)
随机分割数据集多次,每次随机选择一定比例的数据作为训练集和测试集。与k折交叉验证相比,这种方法的灵活性更高,但可能不如前者稳定。
优缺点分析
优点
- 充分利用数据: 特别是在小数据集场景下,交叉验证可以帮助最大化数据的使用效率。
- 减少评估偏差: 多次训练和测试可以减少单次划分可能带来的偶然性。
- 通用性强: 适用于大多数机器学习任务,且能通过不同方法调整以适应特定问题。
- 过拟合检测: 能帮助评估模型是否过度拟合训练数据。
缺点
- 计算成本高: 特别是在模型复杂或数据量大的情况下,需要更长的训练时间。
- 实现复杂性: 相比简单的训练-测试划分,交叉验证需要更多的实现细节。
实践中的应用场景
1. 模型选择
当我们需要在多个模型中选择一个最佳模型时,交叉验证提供了客观的评估手段。例如,在比较线性回归、决策树和支持向量机时,可以使用交叉验证来评估每个模型的平均性能,从而做出最优选择。
2. 超参数调优
许多机器学习模型依赖超参数(如神经网络的学习率、支持向量机的核参数等),交叉验证通过多次测试不同参数组合的效果,帮助我们找到最佳配置。
3. 特征选择
在高维数据集(如文本数据或基因数据)中,选择合适的特征对模型性能至关重要。交叉验证可以用来评估不同特征子集的效果,从而确定最优特征集合。
4. 小样本数据分析
在医学或科学研究中,数据获取成本较高且样本量有限,交叉验证能够有效提高模型评估的可靠性。
实践步骤
- 准备数据: 对数据进行清洗和预处理,包括特征缩放、缺失值填充等。
- 选择验证方法: 根据问题特点选择适合的交叉验证方法(如k折、分层k折或时间序列验证)。
- 模型训练: 在每一轮验证中,使用训练集训练模型,测试集评估性能。
- 性能汇总: 将多次评估结果取平均,作为模型的最终性能指标。
- 优化迭代: 根据评估结果调整模型结构或超参数,重复上述步骤。
总结
交叉验证是机器学习模型评估中的重要工具,通过将数据划分为训练集和测试集的多种组合,能够有效地评估模型的稳定性和泛化能力。尽管计算成本较高,但它在模型选择、超参数调优、小样本分析等场景中都发挥着不可替代的作用。对于每一个追求性能的模型开发者来说,交叉验证都是一个值得掌握和深度理解的技术工具。