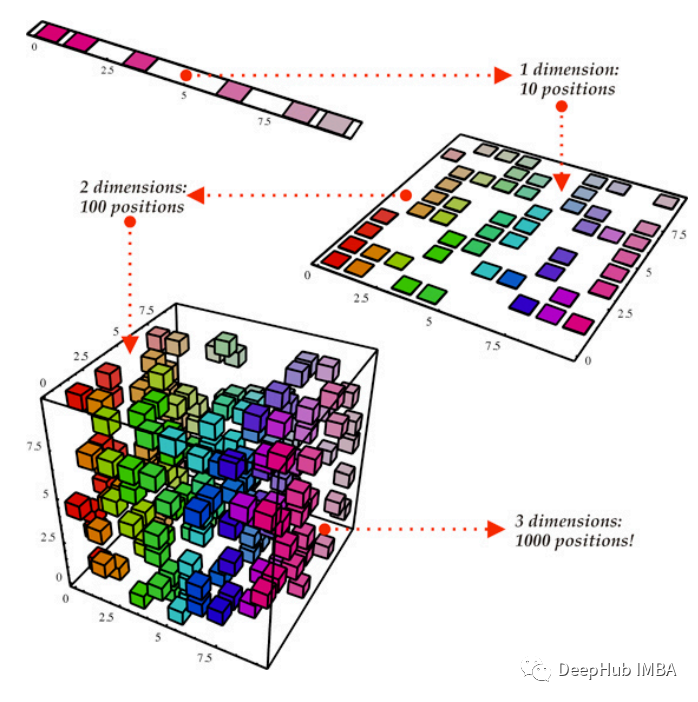
什么是降维算法?
在日常生活中,我们经常会处理数据,比如照片、声音、文字等。随着科技的发展,这些数据变得越来越复杂。假设你拍了一张高清照片,这张照片可能包含数百万像素,每个像素都有多个颜色值(红、绿、蓝)。如果要处理这些数据,计算量会非常庞大。而降维算法就像一个聪明的工具,帮助我们从海量数据中提取最重要的部分,既节省了计算资源,也让我们更容易理解数据。
打个比方:假如你有一本厚厚的书,但你只需要知道书的大概内容,降维算法就像是一本书的摘要,把重要的章节和核心观点提取出来,而不需要逐字逐句去读完整本书。
为什么需要降维?
在实际应用中,数据通常有很多”维度”,比如:
- 一张图片的每个像素就是一个维度。
- 一个购物网站的用户行为数据可能包含性别、年龄、购买记录等维度。
如果数据维度太高,不仅会导致计算量暴增,还可能出现”维度诅咒”问题。维度诅咒是指,随着维度的增加,数据点之间的距离变得越来越接近,导致传统算法难以区分数据特征。
通过降维,我们可以:
- 减少数据存储和计算的压力。
- 去除冗余信息,让数据更容易分析。
- 可视化高维数据,比如把100维的数据投影到2维或3维空间,方便我们用图表展示。
降维算法的两大类型
降维方法可以分为两大类:特征选择和特征提取。
1. 特征选择
特征选择是从现有的维度中挑选出最重要的几个。例如:
- 在预测房价时,与房价关系最密切的可能是房屋面积和位置,而装修风格或邻居数量可能影响较小。我们可以只选择面积和位置作为特征。
- 常用方法包括过滤法(如相关系数)、包裹法(如递归特征消除)和嵌入法(如基于决策树的选择)。
2. 特征提取
特征提取是通过某种转换,将原始数据映射到一个新的低维空间。例如:
- 主成分分析(PCA):找到数据中变化最大的一些方向,把数据投影到这些方向上。
- t-SNE:一种用于可视化的算法,可以把高维数据映射到二维或三维空间,同时尽量保持数据点之间的相对关系。
常见的降维算法
1. 主成分分析(PCA)
PCA 是最经典的降维方法之一。它的核心思想是找到数据中变化最大的方向(称为主成分),然后忽略变化较小的方向。
通俗解释: 假设你有一堆气球,这些气球分布在三维空间中,但实际上它们可能沿着某个方向排列得很紧密。PCA 会找到这个方向,并把数据从三维压缩到一维或二维。
优点:
- 快速高效,适用于大多数场景。
- 能去除数据中的噪声。
缺点:
- 主成分可能不容易解释,比如它们不一定与原始特征直接对应。
2. t-SNE
t-SNE(t-分布邻域嵌入)主要用于数据可视化。它通过保持数据点之间的局部结构,将高维数据映射到二维或三维。
通俗解释: 想象你有一张复杂的地图,t-SNE 会把它压缩到一张小的草图上,同时尽量保留重要的道路和标志。
优点:
- 可视化效果极佳,尤其适合探索数据的分布和分类。
缺点:
- 计算复杂,处理大规模数据时效率较低。
- 结果不具有可重复性,不适合用于预测任务。
3. 自编码器
自编码器是一种基于神经网络的降维方法,它会通过一个瓶颈结构,把数据压缩到低维空间。
通俗解释: 自编码器就像一台压缩机,它会先把高维数据压缩成低维,再尝试还原回来。这个压缩的中间过程就是降维。
优点:
- 可以处理非线性关系的数据。
- 灵活性强,适合复杂任务。
缺点:
- 需要大量数据进行训练。
- 对参数选择敏感。
降维算法的实际应用
1. 图像处理
- 在人脸识别中,PCA 可以用来提取关键特征,比如眼睛、鼻子和嘴巴的位置。
- 降维后可以减少图片存储的大小,同时提高处理速度。
2. 自然语言处理(NLP)
- 词嵌入(如 Word2Vec、GloVe)通过降维把单词映射到低维向量空间,使其更易于处理和比较。
- t-SNE 可以用来可视化文本的语义关系。
3. 医疗数据分析
- 医疗数据往往包含大量变量(如基因表达数据),通过降维可以找到疾病相关的关键基因。
4. 推荐系统
- 在用户与商品交互数据中,降维可以帮助发现用户的潜在兴趣和商品的隐藏特性。
如何选择降维算法?
选择降维算法时需要考虑以下几点:
- 数据的性质:数据是线性还是非线性?
- 目标:是为了可视化、加速计算,还是去噪?
- 数据规模:如果数据量很大,尽量选择计算效率高的算法。
简单建议:
- 如果是线性数据,PCA 是一个很好的选择。
- 如果需要可视化,t-SNE 和 UMAP 是理想工具。
- 如果数据复杂且非线性,可以尝试自编码器。
总结
降维算法是数据科学的重要工具,它帮助我们简化复杂数据,提取核心信息。不管是经典的 PCA,还是新兴的 t-SNE 和自编码器,每种算法都有其独特的优势和应用场景。在实际工作中,选择合适的降维算法,能大大提高数据分析的效率和效果。