聚类算法通俗讲解
聚类算法是机器学习中的一种基本方法,用于将数据集中的数据点按照一定的规则分组,形成多个相互独立的类别。简单来说,聚类就像是把一堆混乱的数据分门别类,让相似的东西归为一类。本文将以通俗易懂的语言,带你了解什么是聚类算法,它的主要类型,以及它在实际生活中的应用。
什么是聚类?
假设你有一篮子水果,包括苹果、香蕉和橙子。它们混在一起,看起来很乱。你想把它们分开,于是按照水果的外形和颜色,把苹果放一堆,香蕉放一堆,橙子放一堆。这就是聚类的一种方式:将相似的事物归为一类。
在计算机的世界里,聚类也是类似的概念。我们将一些数据点(比如客户的信息、图片的像素点等)按照某种规则分组,让每一组中的数据更“相似”,而不同组的数据则“差异更大”。
聚类算法的核心思想
聚类算法的核心可以总结为以下几点:
- 找相似性:
- 比如根据两个数据点之间的距离来衡量它们有多“相似”。距离越近,就越相似。
- 分组:
- 将相似的数据归为一类,不相似的数据划分到不同的组。
- 自动化:
- 聚类是一种无监督学习方法,这意味着它不需要事先标注好的数据(比如不需要告诉计算机某个数据属于哪一类)。
常见的聚类算法
聚类算法有很多种,下面我们通过生活中的例子来说明几种经典的聚类算法:
1. K均值算法(K-Means)
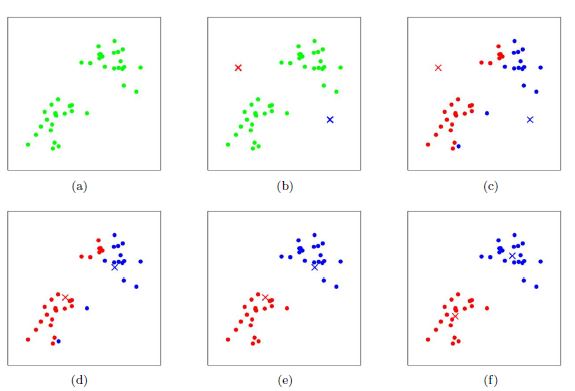
生活例子:假设你和几个朋友站在一个空地上,你们想分成三组。首先,每个人随机站一个位置作为“组中心”。然后,每个人选择离自己最近的中心点,围绕它组成一组。接着,组的中心重新计算,变成组内所有人的平均位置。这个过程反复进行,直到所有人都固定分好组。
算法特点:
- 简单高效,但需要提前指定要分成几组(比如3组)。
- 如果数据分布不均匀,效果可能不好。
2. 层次聚类(Hierarchical Clustering)
生活例子:假设你是一名教师,要把班上的学生分组。你先找出两个最要好的同学,让他们组成一个小组。然后再找出最接近的另一个小组,合并成一个更大的组,依次类推,直到所有学生都在同一个大组里。
算法特点:
- 结果像一棵树,可以随时调整分组的层次。
- 算法灵活,但对大规模数据效率较低。
3. DBSCAN(基于密度的聚类方法)
生活例子:你在一个拥挤的广场上,想找到几个“朋友圈”。你会注意到有些人靠得很近,可以算作一个圈子,而那些离得远的独行者不属于任何圈子。
算法特点:
- 不需要提前指定分成几组。
- 能有效发现任意形状的组,但对参数设置比较敏感。
4. 高斯混合模型(GMM)
生活例子:假设你在分析一家餐厅的顾客来源。餐厅周围有几个不同的社区,每个社区的人都可能会来餐厅消费。根据顾客出现的频率和分布,可以推测出不同社区的边界,虽然这些边界可能是模糊的。
算法特点:
- 能够处理数据之间的模糊分类。
- 比K均值算法更灵活,但计算复杂度更高。
聚类算法的实际应用
聚类算法在生活和工作中有很多实际应用,以下是几个常见的场景:
1. 客户分群
- 应用场景:电商平台希望了解用户的行为习惯,比如有些人喜欢买衣服,有些人喜欢买数码产品。
- 解决方法:通过聚类算法,把客户分为不同的群体,有针对性地推送广告。
2. 图片处理
- 应用场景:你有很多照片,需要根据内容(比如风景、人物等)进行分类。
- 解决方法:聚类算法可以根据像素点的分布,将相似的图片归为一类。
3. 城市规划
- 应用场景:城市管理者想要找到交通拥堵的热点区域。
- 解决方法:通过DBSCAN等算法,分析车辆的行驶数据,找到密集区域。
4. 异常检测
- 应用场景:银行需要检测信用卡是否存在异常交易。
- 解决方法:通过聚类算法发现“不同寻常”的数据点,比如某用户突然进行一笔非常大的交易。
聚类的挑战和局限
虽然聚类算法非常有用,但它也存在一些局限性:
- 需要合理的参数设置:
- 比如K均值算法需要提前指定组数,而这并不总是容易确定的。
- 对数据分布的敏感性:
- 如果数据分布不均匀,某些算法(如K均值)可能无法得到理想结果。
- 维度灾难:
- 当数据的维度过高时,计算距离变得困难,算法性能可能下降。
总结
聚类算法是一种强大的工具,帮助我们理解和整理数据。无论是在电商、交通还是图像处理中,它都能发挥重要作用。通过学习不同的聚类方法,我们可以根据实际需求选择合适的算法。然而,聚类并不是万能的工具,它的效果很大程度上取决于数据的质量和特点。因此,在实际应用中,我们需要结合领域知识和算法技巧,才能取得最佳效果。