什么是强化学习?
我们生活中总能看到这样的场景:小孩学走路会摔倒,但随着尝试次数增加,他会逐渐学会如何站稳和走路;玩电子游戏时,你可能一开始不熟练,但随着失败次数增多,你逐渐掌握了更好的技巧。这种“通过试错和经验改进”的过程就是强化学习(Reinforcement Learning, RL)背后的核心理念。
强化学习是一种人工智能技术,重点在于**“通过奖励和惩罚来让智能体学会完成任务”**。在这个过程中,智能体(也就是系统或程序)会和周围环境互动,不断调整自己的行为,直到找到一个能获得最多奖励的策略。
强化学习的三大核心要素
要理解强化学习,首先要了解它的三大核心要素:
1. 智能体(Agent)
智能体是强化学习的“主角”,它就是那个在学习和探索的“玩家”。在游戏中,智能体可能是控制角色的AI;在自动驾驶场景中,它可能是汽车的大脑。
2. 环境(Environment)
环境是智能体所处的“世界”。智能体的所有行为都会对环境产生影响,而环境也会对智能体的行为作出反馈,比如奖励或惩罚。
3. 奖励(Reward)
奖励是强化学习的“核心驱动力”。当智能体做出正确决策时,会得到奖励;当它做错时,可能会被惩罚。奖励信号就像生活中的老师,指引智能体逐渐朝正确的方向前进。
例如,假设你教一只狗学会握手:
- 如果它伸出爪子,你给它一块饼干(奖励);
- 如果它不动,你不给任何反应(中性反馈);
- 如果它跳到你身上,你说“不行”(惩罚)。
在重复多次后,狗会明白,伸爪子是正确行为,因为它能带来奖励。
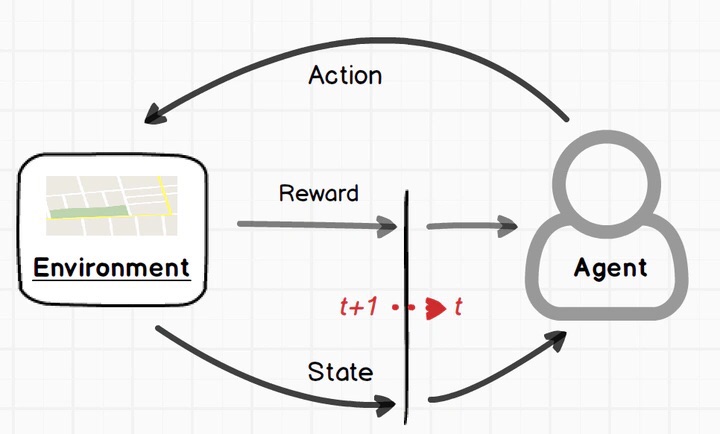
强化学习的工作流程
强化学习的学习过程可以用一个简单的循环来描述:
- 观察环境(Observation):智能体会观察当前环境的状态,比如看到路上的红灯。
- 采取行动(Action):智能体根据观察结果采取一个行动,比如停车。
- 收到反馈(Reward):智能体根据行动收到环境的奖励或惩罚,比如因为停车得到了安全积分。
- 更新策略(Update):智能体通过这个反馈调整自己的策略,争取下次做得更好。
这一过程会不断重复,直到智能体学会最优策略。
强化学习的数学解释(简单版)
虽然我们用生活化的例子解释了强化学习,但它背后其实是一种基于数学的科学方法。强化学习中最重要的两个公式是:
- 奖励信号累计值(Return):
智能体不仅要看眼前的奖励,还要考虑未来的奖励。公式是:Gt=Rt+1+γRt+2+γ2Rt+3+…Gt=Rt+1+γRt+2+γ2Rt+3+…这里的 γγ(折扣因子)决定了未来奖励的影响程度。如果 γγ 越大,智能体越“有远见”。 - 价值函数(Value Function):
价值函数告诉智能体某个状态的“好坏程度”,用于指导它选择行动。
尽管数学复杂,但实际应用时可以通过算法让计算机自动完成这些过程。
强化学习的常见算法
强化学习有许多不同的算法,它们适用于不同的任务场景。以下是几种常见方法:
1. Q学习(Q-Learning)
Q学习是强化学习中最经典的方法之一。它通过学习一个“Q值表”,来帮助智能体判断某个行动在当前状态下的价值。
2. 深度强化学习(Deep Reinforcement Learning, DRL)
这是强化学习和深度学习的结合体。利用神经网络来处理复杂的环境,比如游戏、机器人控制等。Google DeepMind 的 AlphaGo 就是使用深度强化学习的典型案例。
3. 策略梯度方法(Policy Gradient)
这种方法直接优化智能体的策略,让它学会在任何情况下选择最优行动。
强化学习的实际应用
强化学习已经在许多领域展现出了强大的能力,以下是一些实际例子:
1. 游戏AI
强化学习在游戏领域的表现尤为突出。AlphaGo 战胜人类围棋冠军、AI玩星际争霸都是强化学习的成果。
2. 机器人控制
强化学习可以帮助机器人学习走路、跑步甚至爬楼梯。例如,波士顿动力的机器人能够通过强化学习在复杂地形中保持平衡。
3. 自动驾驶
在自动驾驶中,强化学习可以帮助车辆学习如何在复杂道路环境中做出最佳决策,比如避开障碍物、优化行车路线等。
4. 金融交易
强化学习可以用于分析股票市场,帮助交易系统找到最佳买卖时机。
挑战和未来方向
尽管强化学习很强大,但它也有一些挑战:
- 数据效率低:智能体需要大量的试错才能找到最优策略。
- 计算资源消耗大:复杂的环境需要强大的计算能力支撑。
- 安全性问题:在某些场景(如自动驾驶)中,试错成本可能非常高。
未来,研究者们正在探索如何让强化学习更高效、更可靠,比如通过模仿学习(Imitation Learning)或模型学习(Model-based Learning)来减少试错过程。
总结
强化学习是一种“通过试错学习如何决策”的技术,其灵感来源于我们生活中的经验积累。虽然它的数学基础和实现算法可能有点复杂,但核心思想却非常直观:为了达到目标,不断尝试,直到找到最优解。
随着计算能力的提升和算法的改进,强化学习将在更多领域发挥作用,帮助我们解决许多复杂的问题。