什么是欠拟合?
欠拟合(Underfitting)是机器学习中常见的问题之一,它指的是模型在训练数据和测试数据上都表现不佳,无法有效地捕捉数据的模式或规律。换句话说,欠拟合的模型过于简单,以至于无法很好地描述数据的复杂性。
在现实生活中,我们可以把欠拟合比作一个小学生写作文时,只会写非常基础的句子,而无法深入分析问题。例如,面对一个复杂的问题,他只会回答“这个问题很难”,而没有尝试分解问题,给出细致的分析。
欠拟合的特征
欠拟合的模型往往有以下几个特征:
- 训练误差和测试误差都很高:因为模型无法在训练数据上找到有效的规律,所以即使在训练数据上,它的表现也很差。
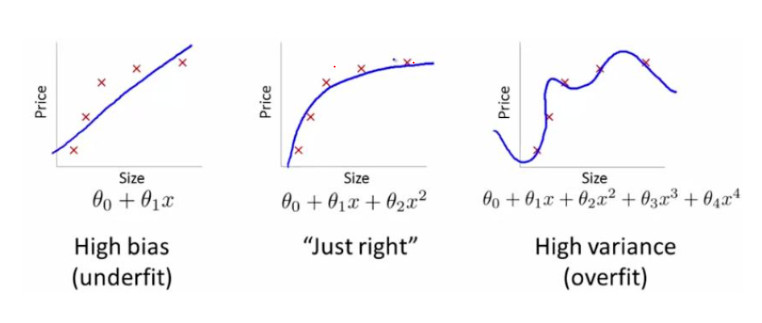
- 模型过于简单:欠拟合通常出现在模型复杂度不足的情况下,例如用一条直线去拟合一个明显是曲线的关系。
- 对数据的变化不敏感:欠拟合的模型对输入数据的细微变化反应迟钝,无法捕捉数据中潜在的结构。
- 结果偏差较大:偏差(Bias)是模型预测值与真实值之间的系统性差距,欠拟合的模型通常会有较大的偏差。
欠拟合的原因
欠拟合的产生原因可以分为以下几类:
1. 模型复杂度不足
如果我们选择的模型太简单,比如线性模型来处理一个非线性的问题,那么模型自然无法很好地拟合数据。例如,用一条直线去拟合一个“U”形的曲线,直线显然无法捕捉到数据的非线性趋势。
2. 数据特征不足
如果训练数据中包含的信息不足以让模型学到规律,那么即使模型再复杂,也无法有效训练。例如,一个分类问题如果只有一个特征,而这个特征不足以区分类别,那么模型可能无法正确分类。
3. 数据预处理不当
欠拟合有时也可能是由于数据预处理的问题导致的,比如:
- 输入数据没有正确归一化或标准化。
- 重要的特征被忽略。
- 数据中存在大量的噪声,掩盖了真正的模式。
4. 训练时间不足
当训练时间太短时,模型可能还没有充分学习数据的模式就停止了训练,从而表现出欠拟合的特征。
如何解决欠拟合?
针对欠拟合问题,我们可以从以下几个方面入手:
1. 提升模型复杂度
如果模型本身过于简单,我们可以通过以下方法增加模型的复杂度:
- 增加模型的参数数量:比如在神经网络中增加隐藏层的数量或每一层的神经元数量。
- 选择更复杂的模型:比如用多项式回归代替线性回归,或者用深度学习模型代替传统的机器学习算法。
2. 提供更多特征
如果训练数据的特征不足,我们可以尝试:
- 增加特征:比如通过特征工程,提取更多有意义的特征。
- 交互特征:将多个特征组合起来,生成新的特征。
- 多项式特征:对特征进行非线性变换,例如添加平方项或三次项。
3. 改善数据预处理
数据的质量对模型的训练效果有直接影响,可以尝试:
- 去噪:清理数据中的噪声。
- 归一化或标准化:确保所有特征的取值范围相近,以避免某些特征对模型产生过大的影响。
- 填补缺失值:处理数据中的缺失值,避免模型因为缺失数据而无法学习。
4. 延长训练时间
如果欠拟合是由于训练时间过短导致的,可以适当延长训练时间,让模型有更多的机会学习数据的规律。
5. 增加数据量
如果数据量不足,模型可能无法学习到足够的规律,这时可以:
- 收集更多数据:增加训练数据的样本数量。
- 数据增强:通过旋转、缩放、翻转等方式生成更多样本。
6. 降低正则化强度
正则化是用来防止过拟合的,但如果正则化强度过大,可能会导致欠拟合。可以尝试:
- 减小正则化参数λ的值。
- 使用更弱的正则化方法。
欠拟合的实际案例
案例 1:线性回归中的欠拟合
假设我们有一个非线性数据集,而我们使用了简单的线性回归模型进行拟合。由于模型的假设是线性的,它无法捕捉到数据中的非线性关系,最终表现为欠拟合。
解决方案:
- 使用多项式回归。
- 提取更多非线性特征。
案例 2:神经网络训练不足
在使用神经网络进行分类任务时,由于训练时间过短,模型的权重还未完全调整到最佳状态。这时,模型对训练数据和测试数据的表现都很差,属于典型的欠拟合。
解决方案:
- 增加训练轮次(epochs)。
- 使用更复杂的网络结构。
案例 3:过强的正则化
在训练一个深度学习模型时,L2正则化参数设置得过大,导致模型过于惩罚权重的增长,结果变成了一个过于简单的模型。
解决方案:
- 减小正则化参数的值。
- 考虑换用其他正则化方法。
欠拟合与过拟合的对比
欠拟合和过拟合是机器学习中的两种常见问题,它们分别对应模型学习能力的两个极端:特征欠拟合过拟合模型表现训练误差高,测试误差高训练误差低,测试误差高模型复杂度过于简单过于复杂偏差与方差高偏差,低方差低偏差,高方差解决方法增加模型复杂度,提供更多特征,延长训练时间减少模型复杂度,增加正则化,获取更多数据
总结
欠拟合是机器学习中必须要解决的问题之一。它的本质是模型无法很好地捕捉数据的规律,通常是因为模型过于简单、数据特征不足或训练不足导致的。通过增加模型复杂度、提取更多特征、改善数据预处理等方法,我们可以有效地缓解欠拟合问题。
在实际应用中,我们需要根据数据和任务的具体情况,合理选择模型的复杂度和训练方法,避免欠拟合和过拟合的同时,实现模型性能的最优化。