机器学习是人工智能的一大分支,而无监督学习是其中一个重要的类型。简单来说,无监督学习就像一个没有老师的学生,面对一堆学习材料,没有现成的答案或者指导意见,只能靠自己去摸索、归纳和总结规律。本文将用通俗易懂的语言,带你一步步理解无监督学习的原理、应用以及它如何改变世界。
什么是无监督学习?
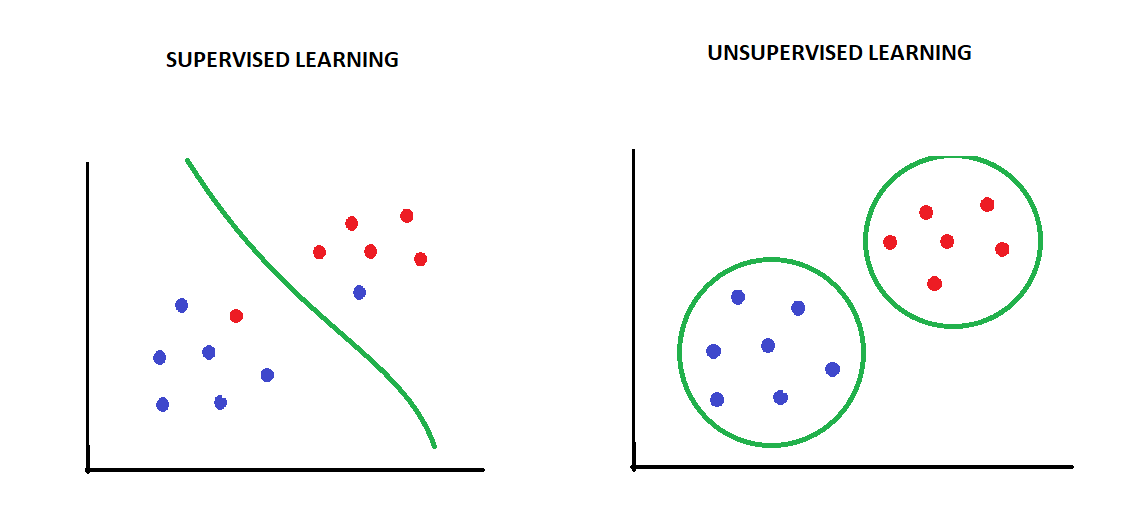
在日常生活中,学习可以分为有指导的和无指导的。例如,小时候学数学,老师会给出题目和答案,这是“有监督学习”;而你第一次尝试用积木搭建房子,没有任何人告诉你怎么做,只能自己摸索,这就很像“无监督学习”。
在机器学习中,无监督学习的核心是:输入大量没有标签的数据,算法会试图发现这些数据的隐藏结构或模式。
举个例子:
想象一个水果市场,算法收到了各种水果的数据(比如大小、颜色、形状等),但没有告诉它每种水果的名字。无监督学习的任务就是根据这些特征,把水果自动分成几类,比如一类是苹果,一类是香蕉,一类是橙子。它不会直接告诉你“这是苹果”,但它会分出“这一堆”看起来很像。
无监督学习的两大核心任务
无监督学习的任务通常可以归结为以下两类:
1. 聚类(Clustering)
这是无监督学习最典型的任务之一。聚类的目标是把相似的对象归为一类。
比喻:
聚类就像整理衣柜,你把长袖、短袖、大衣分开放,但没人告诉你这些类别的名字。
现实应用:
- 社交网络分析:把用户分成不同的兴趣群体。
- 图像分类:在海量图片中找到主题相近的照片。
2. 降维(Dimensionality Reduction)
如果说聚类是把“东西分门别类”,降维就是“简化问题”。
比喻:
想象你要向朋友描述一本书,你不会把每个细节复述一遍,而是概括出几个关键词,比如“科幻”“太空探险”“机器人”,这就是降维的过程——从大量信息中提取出少量核心内容。
现实应用:
- 数据可视化:帮助科学家把复杂的数据投影到2D或3D平面上,更直观地观察模式。
- 推荐系统:比如在音乐应用中,提取歌曲的主要特征,帮用户找到相似的歌曲。
无监督学习如何工作?
无监督学习没有现成的答案,它是怎么“自学”的呢?算法会尝试以下几个步骤:
- 分析数据的特征 假设你有很多个点(数据)分布在二维平面上,算法会先分析这些点的分布情况,比如哪些点靠得近,哪些点离得远。
- 寻找隐藏模式 算法会尝试找到数据的规律,比如哪些点可以分成一类,或者数据可以如何简化。
- 迭代优化 算法可能第一次划分时并不准确,但它会根据某些数学准则(比如让点的分组尽量紧密)不断调整,直到找到一个比较满意的结果。
无监督学习的算法有哪些?
尽管听起来复杂,但无监督学习的方法其实可以归结为一些经典算法。以下是几个通俗易懂的例子:
1. K-Means 聚类
它是怎么做的?
- 假设你想把数据分成 K 类,比如3类。
- 算法随机选出3个“中心点”,然后把所有数据点分配到离它最近的中心点。
- 接着算法调整这些中心点的位置,直到每个中心点刚好“居中”。
比喻:
K-Means 就像你要和朋友在公园里拍照,大家自然会围在最显眼的几个景点周围形成小团体。
2. 主成分分析(PCA)
它是怎么做的?
- PCA 通过数学方法,找出数据中最重要的“维度”。
- 它会把数据“压缩”到低维空间,但尽可能保留数据的主要信息。
比喻:
想象一张巨大的地图上有无数个点,PCA 会找到最适合你的视角,让你从高维的地图中看到清晰的主线。
3. 自编码器(Autoencoder)
它是怎么做的?
- 自编码器是一种神经网络,目的是“压缩”数据再“还原”数据。
- 压缩的过程提取了数据的核心特征,而还原的过程验证这些特征是否足够全面。
比喻:
想象你画一幅画,画完后用很少的笔墨概括出它的精髓(压缩),再根据这几笔还原出完整的画作。
无监督学习的挑战
尽管无监督学习非常强大,但它并非万能,面临一些挑战:
- 结果难以解释 无监督学习的结果往往依赖数学准则,有时候很难用人类的语言解释其意义。
- 没有标准答案 因为没有标签,我们很难判断算法的结果是否真的正确。
- 对数据质量敏感 如果数据本身很乱或者特征选择不当,无监督学习的效果可能会大打折扣。
应用场景
无监督学习已经渗透到我们生活的方方面面:
- 医疗:用来分析基因数据,找到疾病的潜在分类。
- 电商:通过用户的购买记录,分群并推荐更相关的商品。
- 自然语言处理:像 Google 的词向量模型 Word2Vec,就是一种无监督学习方法,帮我们理解词语之间的关联。
总结
无监督学习就像一个好奇心强的探险家,它没有老师,也没有地图,但通过观察和分析,总能发现隐藏在数据中的规律。尽管它不像有监督学习那样“准确”,但它在面对海量、无标签数据时展现了无与伦比的能力。在未来,随着算法和计算能力的不断发展,无监督学习将继续帮助我们解锁数据世界的奥秘。