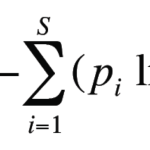
交叉熵的基本概念
什么是交叉熵?
交叉熵听起来像一个复杂的数学术语,但其实它的本质很简单,它是用来衡量两个概率分布之间的“距离”的工具。在人工智能,尤其是深度学习中,交叉熵常常被用作一种损失函数,用来指导模型的训练过程。
想象一下,你是个天气预报员,今天你的任务是预测明天是否会下雨。你说“有80%的概率会下雨,20%的概率不会下雨”。但是到了第二天,实际上却没下雨。此时,就需要有一种方法来评估你的预测到底好不好——交叉熵就是一种评估工具。
简单来说,交叉熵用来回答这样的问题:“我预测得有多接近事实?”
交叉熵源自信息论,它描述了用一个分布去“解释”另一个分布时,平均每个事件需要的额外信息量。在人工智能中,交叉熵的输入是两个概率分布:
- 真实分布(True Distribution): 这是我们期望的输出,比如训练数据中的正确答案。
- 预测分布(Predicted Distribution): 这是模型给出的预测结果。
假如我们用 y 表示真实标签,用 y^ 表示模型的预测概率分布,那么交叉熵的公式如下:H(y,y^)=−i∑yilog(y^i)
虽然公式看起来复杂,但其实它的含义非常直观:
- yi 是真实分布的值,要么是1(正确类别),要么是0(错误类别)。
- log(y^i) 是预测类别的概率的对数值。
- 通过相乘和求和,公式会惩罚那些对正确答案预测得不够“自信”的情况。
举例说明交叉熵
假设我们有一个图片分类任务,目标是判断图片中是否有猫。现在的场景是:
- 真实情况: 这是一张猫的图片(真实标签为 [1, 0],意思是“是猫”的概率是100%,“不是猫”的概率是0)。
- 模型预测: 模型预测的结果是 [0.8, 0.2],即模型认为“是猫”的概率是80%。
代入公式:H(y,y^)=−(1⋅log(0.8)+0⋅log(0.2))=−log(0.8)
在这里,交叉熵的值是模型预测结果与真实答案之间的“误差”。这个值越小,说明模型预测得越接近真实情况。
为什么交叉熵在人工智能中重要?
在人工智能,特别是深度学习中,模型需要通过优化损失函数来提升性能,而交叉熵几乎成为分类任务中的默认选择。原因包括以下几点:
1. 适合概率分布
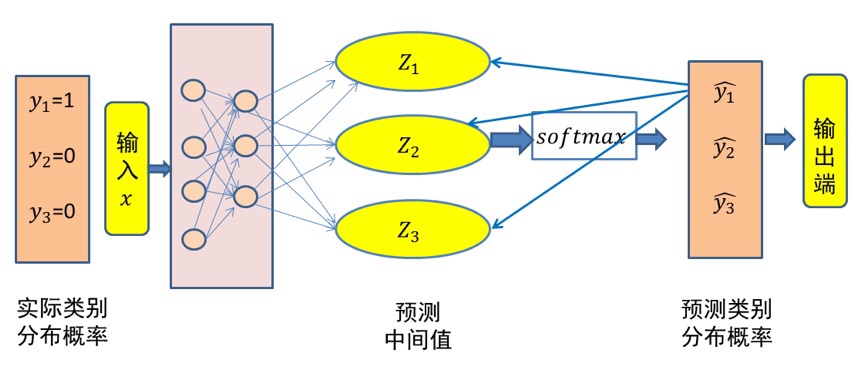
交叉熵直接作用于概率分布,这与神经网络输出层(通常是通过Softmax函数得到的概率分布)高度契合。它能够很好地评估模型的预测概率与真实答案之间的差距。
2. 对错误预测的敏感性
相比于其他损失函数(如均方误差),交叉熵对错误的预测更加“严苛”。如果模型给出错误类别的高概率预测,交叉熵会给予较大的惩罚,这使得模型更快地修正错误。
3. 数学性质优良
交叉熵具有良好的凸性(对于线性模型),在优化过程中表现更为稳定。结合梯度下降算法,它能够高效地帮助模型收敛到一个更优的解。
交叉熵在深度学习中的应用
在人工智能的具体实践中,交叉熵的应用场景非常广泛,尤其是在分类任务中。以下是几个常见的例子:
1. 图像分类
图像分类任务的目标是预测图片属于哪个类别,比如识别图片中的动物是猫、狗还是鸟。通过Softmax函数将模型输出的分数转化为概率,再用交叉熵来计算真实标签与预测概率之间的差距。
2. 自然语言处理
在机器翻译、情感分析等任务中,交叉熵用于衡量模型生成的词语序列与真实答案的相似度。例如,在生成句子“我喜欢吃苹果”时,交叉熵可以计算模型生成“我不喜欢苹果”的错误程度。
3. 语音识别
语音识别模型需要将语音信号转化为文字序列,交叉熵可以帮助模型学习如何更精确地将音频和文字匹配。
交叉熵与模型优化
模型训练的核心是通过梯度下降算法最小化损失函数。交叉熵作为损失函数,其梯度具有明确的方向性,这使得模型能更快、更高效地优化。
在训练过程中,交叉熵通过以下步骤发挥作用:
- 计算预测概率: 模型通过前向传播计算出预测值(通常是一个概率分布)。
- 计算交叉熵损失: 比较预测分布与真实分布,计算误差。
- 反向传播更新权重: 损失值越大,模型会调整权重,减少未来出现类似错误的概率。
通过不断重复这个过程,模型逐渐学会如何做出更接近真实的预测。
交叉熵的局限性
虽然交叉熵非常强大,但它也有一些局限性:
- 对标签依赖性强: 交叉熵需要真实标签为概率分布,如果数据有噪声(比如标签错误),模型会受到较大的影响。
- 对极小概率敏感: 如果模型预测某类别的概率接近0,那么对应的损失值会非常大。这可能导致数值不稳定问题。
- 不适用于回归问题: 交叉熵仅适用于分类任务,对于回归任务(如预测房价)则无法使用。
总结
交叉熵是一种衡量两个概率分布差异的工具,在人工智能中,它被广泛用于分类任务。通过交叉熵,模型可以知道自己的预测与真实答案之间的距离,从而不断调整自身,变得更聪明。
简单来说,交叉熵是人工智能训练过程中的“指南针”,它告诉模型该往哪个方向改进。尽管它不是完美的,但它的高效性和易用性让它成为了深度学习中的“标配”。理解交叉熵,不仅让我们能更好地掌握模型训练的原理,也为开发更强大的人工智能系统奠定了基础。